This is a troubleshooting scenario based on an issue that happened in a production network, namely getting a RST as the third packet in the 3-way handshake.
The flow of this article is as follows: first, we will look at the topology and how the problem manifested itself, then dig deeper and find out the issue. Lastly, we will configure a similar topology in order to recreate what happened.
The network is split up into the resource and the customer areas. They have been given IP addresses from different classes to make it easier to distinguish between them. The point is that the customer network is connected to a shared services network in order to access some resources.
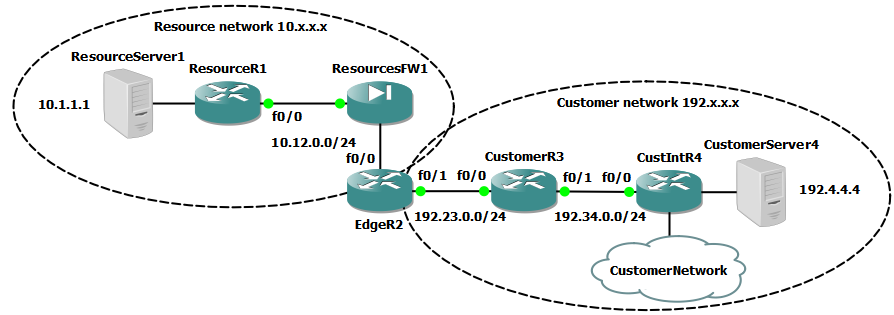
The EdgeR2 router marks the border between the two areas, with ResourcesFW1 guarding against unauthorized access. The routing between them is all static, to keep everything tight and controlled. Also, there aren't many different paths so there is no point to use a routing protocol. All redundancy is missing as well, as it had no role to play in this scenario.
The problem
A trouble-ticket has been raised that an application running on CustomerServer4 192.4.4.4 cannot access resources located on ResourceServer1 10.1.1.1. For the purposes of this lab, consider that the application is good old telnet.
You are the network administrator of the resource network and, as such, you only have access on the devices in this area of the topology.
The investigation
So, first thing you can check is that everything functions properly on your side:
- Firewall logs on ResourcesFW1 - they show that traffic is being allowed between the two servers -
OK - Routing from ResourceServer1 to EdgeR2 -
OK - You get in contact with the admins of ResourceServer1 and CustomerServer4 and ask them to do an end-to-end ping, this also works -
OK - You find out that the application traffic is allowed both ways, so you try to telnet from ResourceServer1 to CustomerServer4, which works -
OK - You ask the CustomerServer4 admin to try again to telnet to ResourceServer1 and, predictably it doesn't work -
NOT OK
So where is the problem? It looks rather weird, but you can conclude that this is due to some asymmetry in your network, given that ICMP and TCP traffic work fine in one direction, but not in the other. The firewall logs show that they passed the packets, but you can't get enough information from that, so you run a packet capture on ResourcesFW1 in order to see if the TCP connection is set up successfully. And here are the results:
Time Source Destination Protocol Info
391.371000 192.4.4.4 10.1.1.1 TCP 32333 > telnet [SYN] Seq=0 Win=4128 Len=0 MSS=536
391.432000 10.1.1.1 192.4.4.4 TCP telnet > 32333 [SYN, ACK] Seq=0 Ack=1 Win=4128 Len=0 MSS=536
391.500000 192.4.4.4 10.1.1.1 TCP 32333 > telnet [RST] Seq=1 Win=0 Len=0
So there we go, the 3-way handshake fails! But look at that, what could prompt the initiator of the connection 192.4.4.4 to send an RST packet as a response to the SYN/ACK received from 10.1.1.1? The negotiation of the parameters of the connection looks fine, so there should be no reason for this rude interruption. So what next?
Remember that up until now, we've only been looking at what happens in our own back yard. But those packets travel through the customer's network as well, so something could happen to them on the way. But with very limited access to the customer network, you need to think about what questions you could ask the people in charge of its administration.
The solution
There are a few options that you can try:
- send the ticket to the customer admins, as it is most likely their problem and they should investigate
- ask them to provide you with a packet capture closer to the source (see below)
- figure out that usually there's some NAT being done to mask customer or other IPs and that while there is no NAT being done on the ResourcesFW1 in this case, it is very possible that there is some on customer devices (far-fetched)
- an admin of the customer network you get in touch with pastes you some NAT configuration from a router (CustomerR3) along the way that affects this traffic (this is what happened)
So what do you get from your colleague from CustomerR3 shows you a few things (output snipped for readability):
interface FastEthernet0/0
ip address 192.23.0.3 255.255.255.0
ip nat outside
!
interface FastEthernet0/1
ip address 192.34.0.3 255.255.255.0
ip nat inside
!
ip nat outside source static 10.1.1.1 192.1.1.1
Packets coming from the resource network towards the customer network are being NATed, but there's nothing that does the same in the other direction. So unless the traffic is initiated from the resource side, the state for NAT will not be created and the traffic will look like this:
Time Source Destination Protocol Info
50.910000 192.4.4.4 10.1.1.1 TCP 32333 > telnet [SYN] Seq=0 Win=4128 Len=0 MSS=536
51.031000 192.1.1.1 192.4.4.4 TCP telnet > 32333 [SYN, ACK] Seq=0 Ack=0 Win=4128 Len=0 MSS=536
51.054000 192.4.4.4 192.1.1.1 TCP 32333 > telnet [RST] Seq=0 Win=0 Len=0
So no wonder CustomerServer4 sends an RST packet. It asked for a connection to 10.1.1.1 and it's getting a response from 192.1.1.1? This is not what it wanted! But because of the NAT being done on CustomerR3, all of this is hidden when looking from the resource network side.
The configuration and the use of the network are inconsistent with the design because:
- the customer doesn't want to have routes for the resource network on the servers - it will access the resource at
10.1.1.1with a customer IP of192.1.1.1. - it has not been so since the beginning, therefore the old configuration is still in place: namely, CustomerServer4 still has a route for
10.1.1.1and the application on it has been configured to use10.1.1.1instead of its NAT IP192.1.1.1. - NAT on the CustomerR3 router has been configured only in one direction.
The solution for this problem is to remove the route that shouldn't be there and that the application should use the correct IP for the connection.
If CustomerServer4 had tried to connect to 192.1.1.1 initially, this whole problem would've been avoided and left undetected.
The lab and configuration
This part explains how to build your own lab to recreate this issue with a simpler topology.
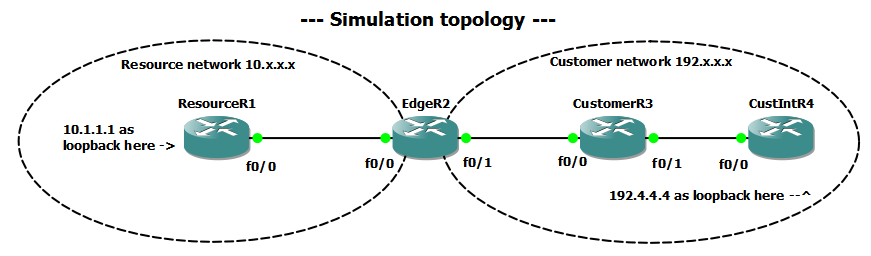
Conventions:
- subnet between resource routers
XandYis10.XY.0.0/24withXhaving10.XY.0.XandYhaving10.XY.0.Y. - subnet between customer routers
XandYis192.XY.0.0/24withXhaving192.XY.0.XandYhaving192.XY.0.Y. - loopback address on
Xis10.X.X.X/32(resource) and192.X.X.X/32(customer)
Configuration:
- Interfaces - check conventions above and diagrams/configs.
- Routing
ResourceR1 has a default route towards EdgeR2 (which in this case would act as the core as well):
Gateway of last resort is 10.12.0.2 to network 0.0.0.0
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 10.12.0.0/24 is directly connected, FastEthernet0/0
C 10.1.1.1/32 is directly connected, Loopback0
S* 0.0.0.0/0 [1/0] via 10.12.0.2
EdgeR2 has static routes for 10.1.1.1/32 and 192.0.0.0/8 (all of the customer network):
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 10.12.0.0/24 is directly connected, FastEthernet0/0
S 10.1.1.1/32 [1/0] via 10.12.0.1
C 192.23.0.0/24 is directly connected, FastEthernet0/1
S 192.0.0.0/8 [1/0] via 192.23.0.3
CustomerR3 has static routes for 10.1.1.1/32 and 192.4.4.4/32 (it doesn't need to know more about the resource network):
192.4.4.0/32 is subnetted, 1 subnets
S 192.4.4.4 [1/0] via 192.34.0.4
10.0.0.0/32 is subnetted, 1 subnets
S 10.1.1.1 [1/0] via 192.23.0.2
C 192.23.0.0/24 is directly connected, FastEthernet0/0
C 192.34.0.0/24 is directly connected, FastEthernet0/1
CustIntR4 has a default route towards some other customer router and a specific route towards the resource ip 10.1.1.1/32:
Gateway of last resort is 192.100.0.1 to network 0.0.0.0
192.4.4.0/32 is subnetted, 1 subnets
C 192.4.4.4 is directly connected, Loopback0
10.0.0.0/32 is subnetted, 1 subnets
S 10.1.1.1 [1/0] via 192.34.0.3
C 192.34.0.0/24 is directly connected, FastEthernet0/0
C 192.100.0.0/24 is directly connected, Loopback1
192.1.1.0/32 is subnetted, 1 subnets
S 192.1.1.1 [1/0] via 192.34.0.3
S* 0.0.0.0/0 [1/0] via 192.100.0.1
Testing end-to-end connectivity:
CustIntR4#ping 10.1.1.1 source loopback 0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.1.1.1, timeout is 2 seconds:
Packet sent with a source address of 192.4.4.4
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 16/45/132 ms
NAT
The customer doesn't want to have routes for the resource network so it will access the resource at 10.1.1.1 with a customer IP of 192.1.1.1.
For this, we will add a route on CustIntR4 for 192.1.1.1 through CustomerR3 and some static NAT on CustomerR3. The NAT will translate packets coming from the resource network from 10.1.1.1 to 192.1.1.1. Considering that the customer IPs are fully routed inside the resource network, there is no need for any other NAT.
CustIntR4(config)#ip route 192.1.1.1 255.255.255.255 192.34.0.3
CustomerR3(config)#ip nat outside source static 10.1.1.1 192.1.1.1
CustomerR3(config)#ip route 192.1.1.1 255.255.255.255 192.23.0.2
Testing
ResourceR1#telnet 192.4.4.4 /source-interface lo0
Trying 192.4.4.4 ... Open
CustIntR4#telnet 192.1.1.1 /source-interface lo0
Trying 192.1.1.1 ... Open
CustIntR4#telnet 10.1.1.1 /source-interface lo0
Trying 10.1.1.1 ...
% Connection timed out; remote host not responding
Solution
CustIntR4(config)#no ip route 10.1.1.1 255.255.255.255 192.34.0.3
And NAT IP of 192.1.1.1 should always be used when accessing the resource server 10.1.1.1 as initially designed.