It all started one morning with a few questions from my colleagues about a VSS deployment, in the context of a major failure that took place the day before. But the biggest question came from the customer: why did it fail when we invested so much money into making it bulletproof?
Why indeed.
For a bit of history, this customer has seen multiple supervisor (SUP) failures in the past on their 6500s while having only 1 SUP in each VSS member. If you lose a SUP, the upstream connectivity stays up but you lose half of your (theoretical, ideal) capacity as one chassis goes down. An obvious big-box style upgrade path was to add another SUP in each chassis to add more redundancy.
Quad-Supervisor VSS is possible and it works like this (source):
- each chassis has a pair of SUPs, 1 is active and 1 hot-standby (called ICS or In-Chassis-Standby)
- the VSS as a whole still has 1 SUP VSS-active (chassis 1) and 1 SUP VSS-hot-standby (chassis 2)
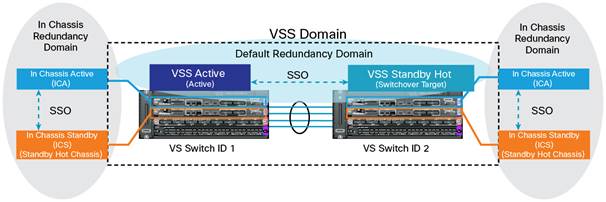
With VS4O the VSS is configured with two supervisor modules per chassis. The second supervisor module within the chassis can be described as an in-chassis standby supervisor (ICS). Within each local chassis the two supervisor modules use Stateful Switchover (SSO) technology to establish an “SSO active” and “SSO standby hot” control plane redundancy relationship. In the unlikely event that the active supervisor should fail, the standby hot supervisor will immediately transition to the active role. This transition occurs in a subsecond manner from the data plane forwarding perspective; in fact, the local chassis remains operational, keeping all links active. In this case we can describe the redundancy relationships as 1:1 within the VSS chassis, followed by 1+1 across the VSS chassis.
As the excerpt above says, there's complete SSO (stateful switchover) capability both intra and inter chassis with Cisco touting sub-second convergence. So what could possibly go wrong?
Quite a bit as it turns out. The customer had two outages that day, one major (reported complete network failure) and one minor (some devices lost connectivity).
The big one
Trying to put together the time-line of what happened was the most difficult part of it all, because of the lack of logs. On inspection, the 6500s did not have a syslog server configured and the log buffer was left at the tiny tiny default of 8k. As you can imagine, most of the useful information was already overwritten by the time we wanted to look at it.
The outage itself was due to the VSS-active SUP crashing, which incidentally is the worst failure scenario you can get. In my opinion it also is the most likely to happen (or rather to be noticed).
No problem you might say, there's 3 other SUPs that will keep things running. And they did, mostly.
As designed, the VSS-active SUP switched to the other chassis (VSS-hot-standby) quickly and seamlessly. But while the crashed SUP was trying to recover, its in-chassis hot-standby SUP did not take over immediately. Predictably, this took out the whole chassis and halved the VSS capacity.
It turns out (according to TAC) that the ICS SUP is rather lukewarm, not hot - it stays partly booted up and if it needs to become active, it will take some time for it to transition to a fully operational state.
About six minutes later (so much for sub-second SSO), said SUP was up and the chassis was back in the VSS, restoring it to its former glory. Even the crashed SUP came online, becoming the ICS SUP.
This was the major outage - where most network connectivity was impaired. But why? Half of the VSS was fully functional. In a typical VSS design you would dual-home your downstream devices to both VSS members. If one chassis goes down, you lose half of the capacity, but you still have connectivity.
But after carefully inspecting the network diagram, it became obvious why they had such a big outage: two thirds of the downstream switches were connected to only one VSS member (the one that suffered the failure, no less)!
The small one
This is just a bonus. Later in the afternoon, the SUP that crashed earlier in the day went down again, this time for good. It was the ICS SUP for that chassis, so theoretically the only things to be seen should've been some logs and SNMP traps.
When that happened, a small part of the network lost connectivity - due to the fact that a downstream switch was connected to a port on the SUP itself. And that was its only uplink.
The problem was swiftly fixed by moving the cable to the SUP that took over. This is redundancy at its best, ladies and gentlemen.
The moral of the story
The major outage was a big deal due to the fact that this particular customer had very high availability requirements from its network. In the end, a single hardware failure coupled with an incomplete deployment (slowly moving migration/refresh projects to dual-home and stack downstream switches) and a not-so-subsecond SSO within the 6500, caused a very unpleasant evening and night for both the customer and the support engineers.
And, to top it all, post-crash investigation was made that much harder as the devices were never deployed to a reasonable minimum standard for operational support.
Unfortunately just having a (theoretically) bullet-proof box does not solve all your problems by itself. In this case it was a very obvious failing once one got a good look at how the whole network was built, but in many cases it can be more subtle than that.
And, as always, thanks for reading.