It's a well known fact that RR (Route Redistribution) is a complicated topic (putting it mildly), and all of you studying for expert level certifications or running old and complicated networks know what I'm talking about. Don't worry, I won't go into a crazy corner-case scenario, this is based on something that happened in a production network.
To start off, I'll list a few things which are relevant to the cases we'll look at below:
- RR is a complex policy-based process.
- Vendor implementations are proprietary (there is no clear standard) and documentation is usually lacking on the finer points.
- A route is redistributed only if it is actively used (installed in the RIB/FIB) and learned via the specified source protocol.
- RR does not impact local route selection (a redistributed route will not replace its source in the RIB).
- Information (metrics, topology) is lost when redistributing from one routing protocol to another (with some exceptions, such as EIGRP<->EIGRP).
The setup
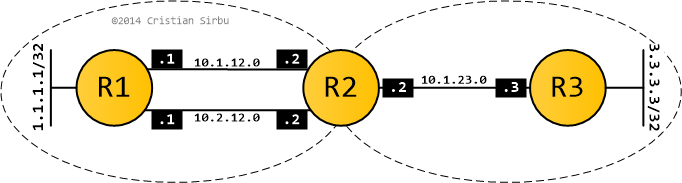
The topology is rather simple: three routers connected as above - so you might be asking yourselves how much mischief can I generate with just 3 routers? The answer is: enough.
The main focus here is the fact that R1 and R2 have two equal cost paths between them, so we'll be looking at what happens when R2 becomes a redistribution point.
R1 advertises loopback 1.1.1.1/32 and R3 sends out its loopback 3.3.3.3/32 and, while I've configured full reachability between them, I'm only interested in the R3 -> R2 -> R1 direction.
OSPF and EIGRP
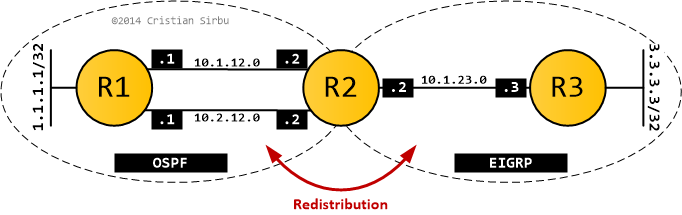
Once the dust settles, the routing tables will have the following information:
#R1
O E2 3.3.3.3 [110/20] via 10.2.12.2, 00:00:02, FastEthernet0/1
[110/20] via 10.1.12.2, 00:00:02, FastEthernet0/0
#R2
O 1.1.1.1 [110/11] via 10.2.12.1, 00:57:30, FastEthernet0/1
[110/11] via 10.1.12.1, 00:57:30, FastEthernet0/0
D 3.3.3.3 [90/156160] via 10.1.23.3, 00:05:45, FastEthernet1/0
#R3
D EX 1.1.1.1 [170/2560002816] via 10.1.23.2, 00:05:31, FastEthernet0/0
First thing that stands out is that R3 has no idea of the equal-cost load-balancing that's done by R2 in the OSPF domain. This is lost information and redistribution does not care about it.
When traffic flows from R3 to R1, it will be load-balanced by R2 over both links. I had to disable per-flow load-balancing (never a good idea outside of a lab) on R2 in order to get the output below and prove it actually works:
R3# trace 1.1.1.1 so lo0
Type escape sequence to abort.
Tracing the route to 1.1.1.1
1 10.1.23.2 28 msec 28 msec 20 msec
2 10.2.12.1 48 msec
10.1.12.1 52 msec
10.2.12.1 36 msec
Why does it work? While R3 has no idea of the OSPF topology, R2 has two routes to 1.1.1.1/32 in its RIB and it's not afraid to use them!
The question screaming for an answer right now is: if R2 has two equal cost routes in its RIB, why doesn't it redistribute both when it exports them from OSPF into EIGRP?
RR is done out of the RIB (routes that are best andin use are a candidate) and it doesn't really matter if this route has one or multiple next-hops. It is reachable via this redistributing router and that's all the destination protocol cares about.
When a packet for 1.1.1.1/32 reaches R2, it's taken care of by the source route (OSPF in this case) in the RIB. It's out of EIGRP's hands.
And even if it had any information about it, EIGRP is a distance-vector protocol. The next-hop is the advertising router, so when R3 gets updates from R2, it will use R2's IPs as next-hops.
Same goes for RIP. OSPF and ISIS calculate the topology themselves and, while they have a full view of their own domain, they know nothing about other routing domains (information lost while redistributing).
OSPF and BGP
What about BGP, you might be asking. It's a protocol that propagates next-hop information so it must do something differently. Well, sort of.
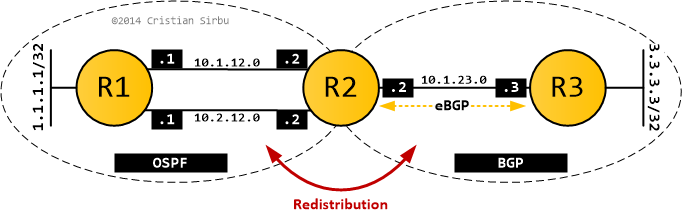
After I replace the EIGRP adjacency with an eBGP peering, the routing tables have the following information:
#R1
O E2 3.3.3.3 [110/1] via 10.2.12.2, 00:01:04, FastEthernet0/1
[110/1] via 10.1.12.2, 00:01:04, FastEthernet0/0
#R2
O 1.1.1.1 [110/11] via 10.2.12.1, 00:02:09, FastEthernet0/1
[110/11] via 10.1.12.1, 00:02:09, FastEthernet0/0
B 3.3.3.3 [20/0] via 10.1.23.3, 00:00:49
#R3
B 1.1.1.1 [20/11] via 10.1.23.2, 00:00:33
And, again, the traceroute shows us loadbalancing works:
R3# trace 1.1.1.1 so lo0
Type escape sequence to abort.
Tracing the route to 1.1.1.1
1 10.1.23.2 20 msec 28 msec 20 msec
2 10.1.12.1 [AS 2] 48 msec
10.2.12.1 [AS 2] 36 msec
10.1.12.1 [AS 2] 44 msec
The end result is identical to the previous case. When looking at the BGP table on R2, we can see it has taken the 1.1.1.1/32 prefix with a next-hop of 10.1.12.1. Is this arbitrary? Not really. It looks like it chooses the lowest next-hop IP address - this is based on observation, as I couldn't find anything in Cisco's documentation about it.
R2# show ip bgp 1.1.1.1
BGP routing table entry for 1.1.1.1/32, version 4
Paths: (1 available, best #1, table Default-IP-Routing-Table)
Local
10.1.12.1 from 0.0.0.0 (2.2.2.2)
Origin incomplete, metric 11, localpref 100, weight 32768, valid, sourced, best
This being an eBGP peering, the next-hop changes when the prefix is passed on to R3:
R3# show ip bgp 1.1.1.1
BGP routing table entry for 1.1.1.1/32, version 2
Paths: (1 available, best #1, table Default-IP-Routing-Table)
10.1.23.2 from 10.1.23.2 (2.2.2.2)
Origin incomplete, metric 11, localpref 100, valid, external, best
Had this been iBGP instead, then R3 would've done a recursive lookup for 10.1.12.1 and resolved it towards R2. Once the packet got to R2 though, it would've been forwarded according to R2's RIB (with the two equal cost paths).
Wrapping up
So we've seen that the destination protocol has no idea if any load-balancing is happening on the other side, even when this is as close as the redistributing router itself.
In the examples above there is no real downside and routing functions as you'd expect it to. That's about to change though: in part 2, I'm bringing VRFs and MPBGP into the picture and, as you might expect, something will go wrong.
And, as always, thanks for reading.